The Reason
Confession time—I like collecting hardcover books…but not just for the obvious reason of reading them. Don’t misunderstand me, I have read a good number of the books on my bookshelves, and of course I have favorites that I’ll read once or twice a year. But I also have books in my home that I have not read, some recently purchased, others I’ve had for years. The reason they’re on my bookshelf? It might sound vain, but they look nice; they’re the right size, the right thickness, they’re hardback, and the right color (jackets removed, of course) to complement the surrounding décor and make the space feel cozy and aesthetically pleasant. Sure, I’m displaying some books I’ve never read—but without them, the space wouldn’t feel as complete.
I’m also sure that out of those books I haven’t read, if I were to read some of them, I might not end up keeping them; despite their perfection in all other ways, they could very well be terrible books with spongy plots, historical inaccuracies, or overzealous antagonists. So, I have to ask myself the question—would I knowingly keep a book like that on display for the sake of appearance?
Of course, I would.
The Rant
How many reports in your inbox or dashboards in your reporting tool look like one of those books? You know the data is a mess, or uses faulty methodology to collect the data, and poor maintenance to update the data. You know how many times you’ve had to go back to source data to attempt to get clarity on the location of the field. You know those Net Promoter Scores (NPS) are only informed by a portion of your customer base and that you aren’t really calculating Monthly Recurring Revenue (MRR) correctly. Yet, you keep the book on the shelf—opening it up only to confirm the antagonist is still overzealous and the plot is still porous in later chapters.
Why don’t you take it off the shelf?
It looks nice.
I’ll never fully understand why we choose to display inaccurate or incomplete data in our dashboards and reports. It’s okay to incorporate the data and through that process discover it’s inaccurate or incomplete…that’s preferred because it means you’ve actually read the book. What’s not okay is not knowing and making data-driven decisions based on unvalidated data that isn’t t reflective of the true story.
Data-driven decisions—with how many times we’ve all heard this phrase over the last few years, how many people actually know what it means? No trick questions here…it literally means making decisions based on supporting data. So why then, for something that’s so simply defined and direct, does it feel like we conceptualize it as a philosophy rather than a practical, executable approach to maturing the business? Again…the answer is in the phrase. Data.
We long for the ability to make data-driven decisions but lack the vision and restraint to make decisions to drive data; we move too fast and overlook basic foundational building blocks in our data, that if we were to slow down to correct, would enable us to be accurately led by our data. Why? Unfortunately, the answer to that question isn’t as simple as pomp and circumstance. We have initiatives to drive, objectives to exceed, deadlines to meet, backlogs to prioritize, timelines to accelerate, and value to demonstrate internally to stakeholders and externally to customers.
The Resolution
So, we have two questions to answer—1. How do we make decisions to drive data? 2. How do we practically apply clean, accurate data to make truly data-driven decisions?
Let’s start with the former—How do we make decisions to drive data?
- Low hanging fruit
In a moment, you’re going to see some flashy dashboards and data points that may be aspirational compared to your current data structure and capability. That’s okay. Start where you are, not where others are telling you to start. For example, if you know your NPS data is solid and complete, build a custom report or dashboard for it. You can (and should) layer in other variables as your business matures. Eat the low-hanging fruit while it’s ripe instead of stretching beyond your reach to pick the not yet matured apples at the top of the tree. - Decisions to drive data. The decision to drive towards quality in your data isn’t owned by a single person or organization—it’s a company-wide initiative. I fully acknowledge that it can be hard to flag data issues. Maybe you don’t know who to report them to. Maybe the data stewardship isn’t clearly defined. Maybe you only have your direct manager to notify. Regardless of internal politics, start the conversations and move towards action. Data is often viewed as an intangible—you can’t touch it so why should you have to fix it? Stop this mentality and work towards resolution, halting the reporting and usage of that specific data point until resolved. CSMs should be flagging and reporting inaccurate or incomplete data. And CS Operations can do even more. We can drive the cross-functional conversations necessary to enable or add fields, define company-wide metrics, and collaborate to establish governance policies where they don’t exist before. As CS Operations, we have to decide that we are going to own the initiative and execute, fully recognizing it’s an iterative process and perfection is the enemy of good.
- External reporting tool. This one is kind of a sidebar, but a concept that I fully endorse and have seen work well when executed properly. Regardless of what your technology stack looks like, I highly recommend an external business intelligence and visualization tool. I don’t care which one. It’s likely your company already has access to one of the big three: Power BI, Domo, or Tableau. Leverage it! There are a variety of automation and connection possibilities to operationalize the data ingestion; there is a reason these tools are designed this way. Keeping sales dashboards in your CRM and Customer Success dashboards in your Customer Success platform is fine—I’m not suggesting we stop utilizing the reporting and dashboard capabilities that exist within those platforms. But think about the purpose of CRMs and CS platforms for a minute. The CRM is designed to track and monitor opportunities through the sales cycle. (Of course, there are other features and customization you can create in a CRM, but the main use case still centers around tracking potential spend.) Now think about the use case for Customer Success tools. Regardless of which vendor you choose, the design is to enable insight into the customer to be able to proactively drive value. (That may be a bold understatement, but again…keeping it big picture.) In short, the CRM is the tool for a Sales Rep’s day-to-day activity and the CSP is the tool for a CSM’s day-to-day activity. So, why are we expecting either of those tools to be adequate to report the metrics we need to the executive level, or even have the data needed to conveniently do so? They can certainly get you part of the way there, but you’ll give yourself much more autonomy by turning to the robust features that a BI tool can provide.
Now let’s dive into the latter—How do we practically apply clean, accurate data to make data-driven decisions?
I’m only going to go over some basics here. If you’re really looking for a thorough, comprehensive deep-dive into the actual ‘how’ and ‘why’ behind the methodology, and the knowledge to execute, I recommend checking out Ed Powers’ course on Udemy.
But let’s look at some practical applications of what it means to make decisions based on data. If this feels foundational to you, that’s because it is, but I think we could all use a refresher. It’s also best to assume that for the example below, the data has been vetted, validated, and confirmed to be accurate. Take the time to thoroughly digest what you’re seeing. The hardest part of this entire exercise is taking the time to read the data. It can be presented in the most clear, crisp format, but you still have to read it before it can inform your decisions.
If you’re a regular around here, these examples should look familiar.
(NOTE: all data displayed in the following dashboards has been fabricated for the purpose of example.)
EXAMPLE 1:
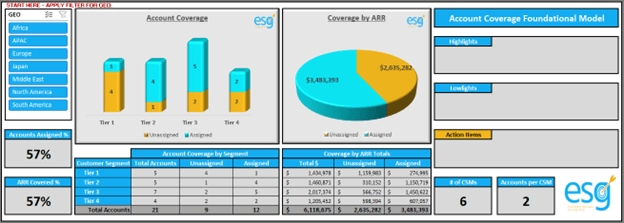
EXAMPLE 2:

EXAMPLE 3:
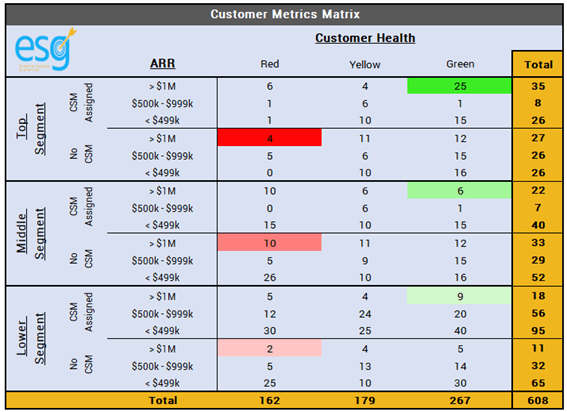
Using the individual examples above, think about the following questions for each—
- What stands out to you most?
- Is there anything that doesn’t look accurate to you in the data?
- What do you see as the biggest action item from the data presented?
- Are there any data points that contradict your expectations?
- What decisions would you make that are directly influenced by the data?
The tricky part is each one of you reading this potentially answered those questions differently. We all come in with our individual cognitive biases based on our own experiences and prioritized initiatives we are currently working through. Someone focusing on NPS implementation right now may have read example two and completely focused on the amount of work needed to remediate all those detractors. Maybe someone else who is focused on driving advocacy programs for their organization read the same example and was drawn towards the high number of potentially ideal champions based on their overall customer experience. Neither person would be wrong. But neither person would be entirely correct either.
We must look at our data in a more holistic and complete way. We can’t pick and choose what we want to pay attention to and what we want to ignore, especially if we know it’s quality data. In order to make data-driven decisions, we have to learn how to read the data—and as CS analysts, it’s our job to tell that story in a way that mitigates the influence of bias. And although we’ll write the story, you need to be the one to read it.
Until next week.
Missed last week’s installment of Rants of a Customer Success Analyst? Go back and read! And keep an eye out for the next Reason, Rant, and Resolution next week.